Watchdog y Self-Healing: La Guía para una Casa que se Repara Sola
Aprende a configurar un sistema watchdog y self-healing en Home Assistant para que tu domótica detecte fallos y se recupere sola, sin que tengas que tocar nada.
En este artículo:
- La noche que todo dejó de funcionar (y nadie se dio cuenta hasta el día siguiente)
- ¿Qué es un Watchdog y por qué tu domótica lo necesita?
- Los fallos más comunes que un watchdog puede resolver
- Arquitectura de un sistema self-healing en Home Assistant
- Cómo detectar dispositivos offline en Home Assistant
- Cómo reiniciar dispositivos automáticamente en Home Assistant con enchufes
- Watchdog para Zigbee: cómo detectar y recuperar dispositivos caídos
- Watchdog con Node-RED: monitorización visual y lógica avanzada
- Notificaciones accionables: cuando el self-healing no puede solo
- Cómo hacer un watchdog en Home Assistant paso a paso
- Comparativa: métodos de watchdog en Home Assistant
- Errores comunes al montar un sistema watchdog
- Mejor opción según tu nivel
- Dispositivos recomendados para un sistema self-healing robusto
- Experiencia real tras 6 meses usando watchdog
- FAQ
- Conclusión: tu domótica tiene que trabajar aunque tú duermas
La noche que todo dejó de funcionar (y nadie se dio cuenta hasta el día siguiente)
Eran las 2 de la mañana. El router de IoT se había colgado. Los sensores de movimiento llevaban horas sin reportar nada, el termostato inteligente no recibía órdenes y las persianas automatizadas simplemente no respondían. Nadie se enteró hasta la mañana siguiente, cuando al levantarse la casa no hizo absolutamente nada de lo que se suponía que debía hacer.
Ese día Javier, que lleva años montando sistemas domóticos, llegó al trabajo con cara de sueño y con una idea fija: que la casa aprendiera a detectar sus propios fallos y repararlos sola. Sin depender de nadie. Sin tener que reiniciar nada manualmente.
Eso es, exactamente, lo que vas a aprender en esta guía.
Respuesta rápida: Un watchdog en Home Assistant es un sistema que monitoriza continuamente el estado de tus dispositivos. Si quieres aprender cómo detectar dispositivos offline en Home Assistant (un sensor sin señal, un broker MQTT caído), esta es la solución. Cuando el watchdog detecta el fallo, ejecuta el self-healing: logra reiniciar dispositivos automáticamente en Home Assistant sin que tú intervengas.
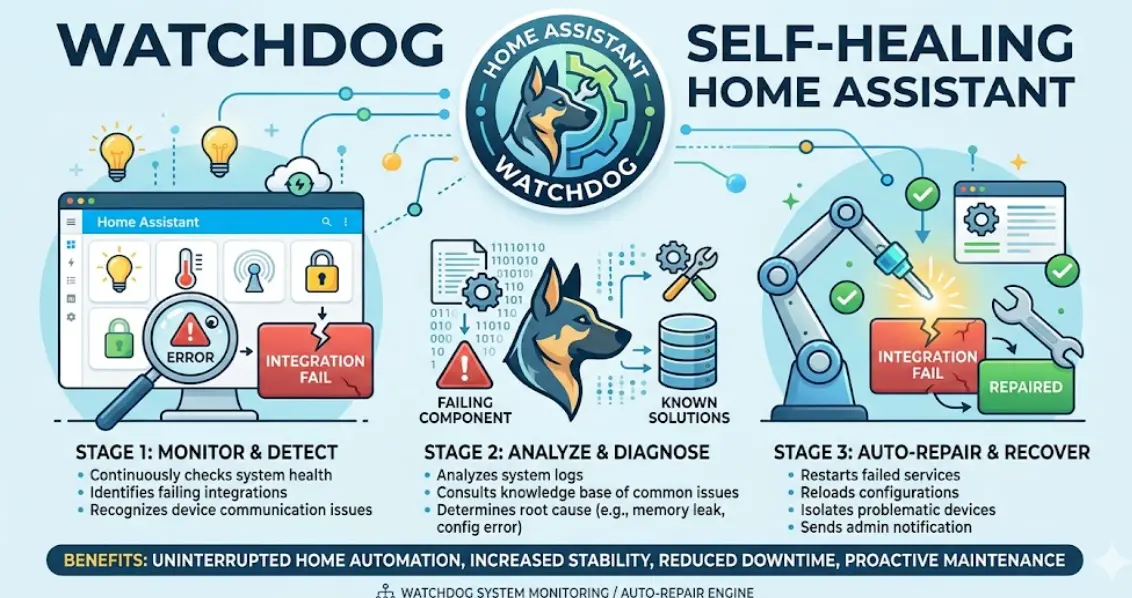
¿Qué es un Watchdog y por qué tu domótica lo necesita?
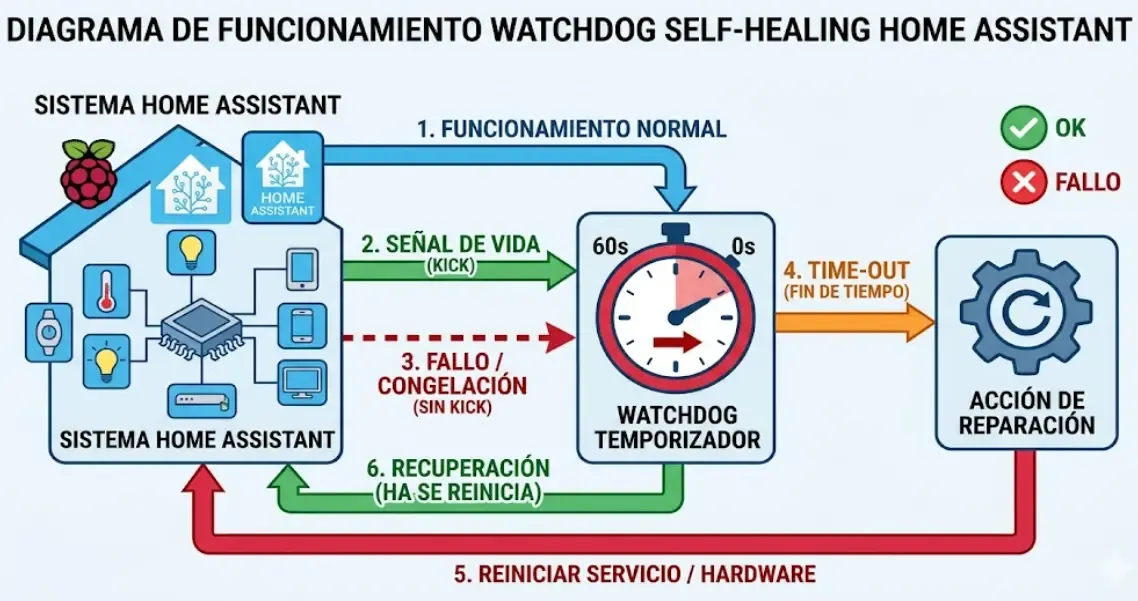
Un watchdog es un mecanismo de supervisión que comprueba periódicamente si un sistema funciona correctamente. Si en un tiempo determinado no recibe una señal de “todo bien”, asume que algo ha fallado y toma una acción correctiva.
En el mundo embebido y de servidores esto lleva décadas siendo estándar. En domótica casera, sin embargo, la mayoría de la gente todavía arregla los problemas a mano, muchas veces sin saber siquiera que algo falló horas antes.
María lo explica bien: “El problema no es que los dispositivos fallen. Es que no te enteras. Y cuando te enteras, ya ha pasado un día entero con la automatización del riego sin funcionar, o con el sensor de CO₂ sin datos.”
El self-healing va un paso más allá: no solo detecta el fallo, sino que lo resuelve solo. El sistema se autorepara. Reinicia lo que haga falta, recarga lo que esté bloqueado, y si no puede resolverlo solo, te manda una notificación clara con lo que ocurre.
💡 En resumen, así funciona un watchdog: Si falla MQTT: El sistema recarga la integración sola. Si un sensor no reporta: Te llega una alerta temprana al móvil. Si el router de IoT muere: Un enchufe inteligente le corta la corriente y lo reinicia.
Los fallos más comunes que un watchdog puede resolver
Antes de ponerse a configurar nada, hay que entender qué tipo de fallos son los más frecuentes. Lucía los tiene muy claros porque los ha sufrido todos:
Dispositivos Zigbee que se caen del mesh. Ocurre más de lo que parece, especialmente con dispositivos que están en los límites de cobertura. El coordinador los pierde y ya no vuelven solos. Saber más sobre redes Zigbee y cobertura.
El broker MQTT que deja de responder. Mosquitto se bloquea, o simplemente pierde la conexión con algunos clientes. Si no hay nadie mirando, llevas horas sin telemetría. cómo configurar MQTT en Home Assistant paso a paso
Integraciones de Home Assistant que se “quedan colgadas”. La integración de Tuya, de Sonoff o de cualquier nube de terceros a veces pierde el token o sufre un timeout. Sin un watchdog, esos dispositivos aparecen como “no disponible” hasta que alguien recarga la integración a mano.
Sensores que dejan de enviar datos. Un sensor de temperatura que no actualiza desde hace 30 minutos puede significar que la batería está muerta, que se cayó del mesh, o que simplemente se fue. Sin un sistema de monitorización activa, no lo sabes.
Routers o dispositivos Wi-Fi que pierden conexión. Para esto, la integración nativa Ping (ICMP) de Home Assistant es tu mejor aliada. Un binary_sensor de ping te dice al instante si el dispositivo físico (como una cámara o el router de la operadora) está caído de la red, sin necesidad de usar plantillas complejas.
El propio Home Assistant o Node-RED bloqueados. Raro, pero pasa. Un flujo mal diseñado en Node-RED puede generar un bucle que consuma toda la CPU. Un SAI bien configurado evita apagones, pero no bloqueos de software.
Arquitectura de un sistema self-healing en Home Assistant
Javier insiste en que antes de escribir una sola línea de YAML hay que tener clara la arquitectura. Un sistema de watchdog bien diseñado tiene tres capas:
Capa 1 – Detección: Sensores virtuales, plantillas y monitores que comprueban continuamente el estado del sistema.
Capa 2 – Decisión: Automatizaciones o flujos de Node-RED que evalúan si el fallo es real o un falso positivo, y deciden qué acción tomar.
Capa 3 – Recuperación: Las acciones concretas: reinicio de servicio, recarga de integración, notificación o acción física (como cortar y reponer la corriente a un dispositivo vía enchufe inteligente).
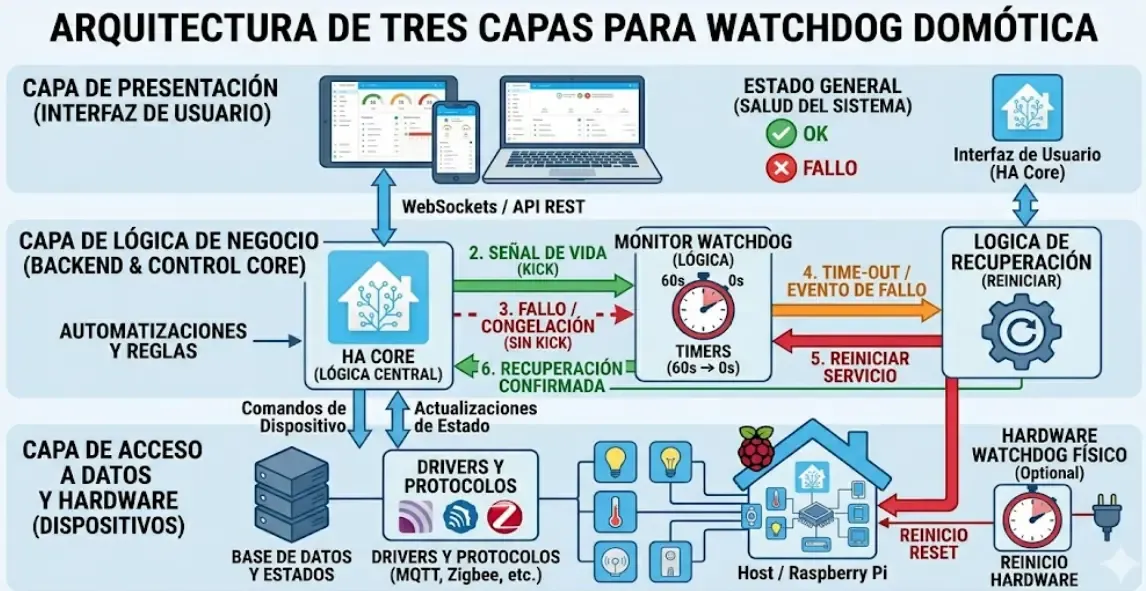
Esta separación es clave. Si mezclas detección con acción en la misma automatización sin una capa de decisión intermedia, acabas con sistemas que se reinician solos cada vez que hay una microdesconexión de 2 segundos, que es exactamente lo que no quieres.
Cómo detectar dispositivos offline en Home Assistant
Plantillas de disponibilidad y sensores de tiempo sin datos
La herramienta más potente para watchdog en Home Assistant son las plantillas Jinja2. Con ellas puedes crear sensores virtuales que evalúen, por ejemplo, cuánto tiempo lleva un sensor sin actualizar su estado.
template:
- sensor:
- name: "Sensor temperatura salón - tiempo sin datos"
state: >
{% set sensor = states.sensor.temperatura_salon %}
{% if sensor is not none and sensor.last_updated is not none %}
{{ (now() - sensor.last_updated).total_seconds() / 60 | round(1) }}
{% else %}
0
{% endif %}
unit_of_measurement: "min"Con ese sensor puedes crear una automatización que se dispare si llevan más de 15 minutos sin actualizar:
automation:
- alias: "Watchdog - Sensor temperatura salón sin datos"
trigger:
- platform: template
value_template: >
{{ states('sensor.temperatura_salon_tiempo_sin_datos') | float > 15 }}
action:
- service: notify.telegram
data:
message: "⚠️ El sensor de temperatura del salón lleva más de 15 min sin actualizar"Watchdog MQTT en Home Assistant (ejemplo real)
Muchas integraciones exponen un sensor de conectividad o un atributo available. Puedes crear un grupo binario que monitorice el estado de tus integraciones críticas y disparar una recarga automática si alguna cae.
automation:
- alias: "Watchdog - Recargar integración MQTT si no disponible"
id: "watchdog_reload_mqtt"
mode: single
trigger:
- platform: state
entity_id: binary_sensor.mqtt_conectado
to: "off"
for:
minutes: 2
action:
- service: homeassistant.reload_config_entry
data:
entry_id: "{{ state_attr('binary_sensor.mqtt_conectado', 'config_entry_id') }}"Cómo reiniciar dispositivos automáticamente en Home Assistant con enchufes
Este es el consejo que más veces ha dado Javier en el grupo y que menos gente aplica: poner los dispositivos críticos de red en enchufes inteligentes con medidor de consumo.
La idea es simple. Si el router de IoT lleva X minutos con consumo anormalmente bajo (o cero), o si el coordinador Zigbee no responde, la automatización corta la corriente 10 segundos y la repone. Un reinicio hardware limpio, sin tocar nada.
Para esto funcionan muy bien los enchufes con medidor de consumo. El consumo en vatios actúa como señal de vida: si baja de un umbral, algo va mal.

Shelly Plus Plug S - Enchufe Inteligente con Monitorización de Consumo
Ideal para watchdog hardware: monitoriza el consumo de tus dispositivos de red y reinícialos automáticamente cuando el consumo cae a cero o se detecta un fallo. Compatible nativamente con Home Assistant vía integración local.
El Shelly 1PM Mini Gen3 también es una opción excelente si quieres integrar el watchdog directamente en el cuadro eléctrico o en un rack doméstico.
Pro Tip 2026: Antes de crear la automatización, revisa si tu dispositivo (como los nuevos Shelly Gen3) tiene Watchdog local en su propio firmware. Esto permite que el enchufe se reinicie a sí mismo si pierde el ping al router, sin depender de que Home Assistant esté online.
Watchdog para Zigbee: cómo detectar y recuperar dispositivos caídos
Zigbee es robusto, pero no infalible. Si tienes ZHA o Zigbee2MQTT, puedes monitorizar el LQI (calidad de enlace) y el tiempo desde el último mensaje de cada dispositivo.
En Zigbee2MQTT, cada dispositivo expone un sensor last_seen. Una plantilla que compruebe si ese valor supera los 30 minutos te da una alerta temprana antes de que el dispositivo desaparezca del todo.
template:
- binary_sensor:
- name: "Sensor puerta garage - offline"
id: "sensor_garaje_watchdog"
state: >
{% set last = states('sensor.puerta_garage_last_seen') %}
{% if last and last not in ['unknown', 'unavailable'] %}
{{ (now() - as_datetime(last)).total_seconds() > 1800 }}
{% else %}
true
{% endif %}Nota importante: Para que esta plantilla funcione, asegúrate de tener activada la opción last_seen en la configuración de Zigbee2MQTT. Ve a Settings > Advanced y configura last_seen en formato ISO_8601 o epoch.
Si el dispositivo lleva mucho tiempo sin responder, el primer paso es hacer un permit_join durante 60 segundos para que vuelva a hacer el par. Si eso no funciona, el watchdog puede reiniciar el coordinador Zigbee vía el enchufe inteligente donde está conectado.
Si se cae el mesh Zigbee, a veces la culpa es de un coordinador débil.

SONOFF Zigbee 3.0 USB Dongle Plus
El coordinador Zigbee más estable para Home Assistant. Si tus dispositivos se caen constantemente del mesh, actualizar tu antena es el primer paso antes de configurar un watchdog.
Watchdog con Node-RED: monitorización visual y lógica avanzada
Para sistemas más complejos, Node-RED ofrece una ventaja enorme: puedes ver el estado de todos tus watchers en un solo dashboard de flujos, con colores que indican OK o fallo en tiempo real.
El patrón más útil es el heartbeat check: un nodo inject que envía un ping cada 5 minutos a los servicios críticos (MQTT, Home Assistant API, Zigbee2MQTT), y un nodo que evalúa si la respuesta llega en menos de 2 segundos. Si no llega, dispara la acción de recuperación.
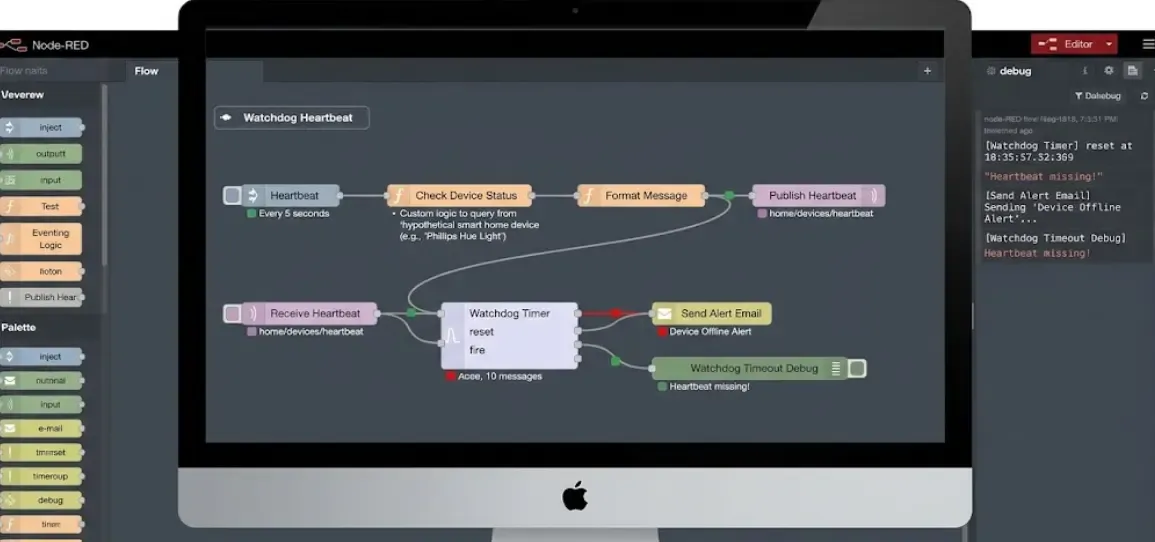
Con la paleta node-red-contrib-ha-websocket puedes también suscribirte a los eventos de Home Assistant y reaccionar en tiempo real a cambios de estado de disponibilidad, sin necesidad de polling.
Notificaciones accionables: cuando el self-healing no puede solo
No todo tiene solución automática. Cuando el sistema detecta un fallo que no puede resolver (un dispositivo físicamente desconectado, una bombilla fundida, una batería agotada), lo correcto es escalar al humano con una notificación accionable.
action:
- service: notify.mobile_app_tu_movil
data:
title: "Watchdog: Nodo Zigbee Caído"
message: "El sensor de inundación no responde."
data:
actions:
- action: "RELOAD_ZIGBEE"
title: "Recargar Red"
- action: "IGNORE"
title: "Ignora"La clave es que la notificación sea útil, no ruidosa. Lucía lo aprendió a las malas: “Tuvimos un sistema que mandaba notificación por cada sensor que se quedaba sin batería. Al tercer día de recibir 12 alertas al día, desactivé las notificaciones. Peor el remedio que la enfermedad.”
El truco es agregar las alertas: una sola notificación diaria con un resumen de todos los dispositivos que necesitan atención, más alertas inmediatas solo para fallos críticos (coordinador Zigbee offline, Home Assistant no responde, etc.).
# Ejemplo de notificación accionable por Telegram
automation:
- alias: "Watchdog - Notificación Crítica MQTT"
trigger:
- platform: state
entity_id: binary_sensor.mqtt_conectado
to: "off"
for: "00:05:00"
action:
- service: notify.telegram
data:
message: "🚨 El Broker MQTT lleva 5 minutos caído. ¿Intento un reinicio forzado desde el enchufe inteligente?"
data:
inline_keyboard:
- "Sí, reiniciar enchufe:/reiniciar_mqtt"
- "No, lo reviso yo:/ignorar_mqtt"Cómo hacer un watchdog en Home Assistant paso a paso
Cómo configurar un sistema watchdog básico en Home Assistant
Configura tu primer sistema de monitorización y auto-recuperación en menos de 30 minutos usando YAML y automatizaciones nativas.
Identifica tus dispositivos críticos
Haz una lista de los dispositivos y servicios que, si fallan, afectan más tu rutina: coordinador Zigbee, broker MQTT, router de IoT, sensores de seguridad. Estos son los que necesitan watchdog prioritario.
Crea sensores de tiempo sin datos
Usa plantillas Jinja2 para crear sensores que midan cuántos minutos llevan tus dispositivos críticos sin actualizar su estado. Guárdalos en un paquete YAML separado para mantener el orden.
Define umbrales de alerta
Para sensores de temperatura o humedad, 30 minutos sin datos es un umbral razonable. Para el broker MQTT o el coordinador Zigbee, 2-5 minutos ya es crítico. Ajusta según el tipo de dispositivo.
Crea las automatizaciones de recuperación
Para cada fallo detectado, define una acción. En lugar de complicarte con comandos SSH, usa la acción nativa de Home Assistant para recargar la integración fallida (homeassistant.reload_config_entry), o corta y repón la corriente al dispositivo mediante un enchufe inteligente.
Configura notificaciones de escalado
Si tras el intento de autorrecuperación el problema persiste, manda una notificación por Telegram o por la app de Home Assistant con el nombre del dispositivo, el tiempo que lleva fallando y las acciones ya intentadas.
Prueba el sistema
Desconecta manualmente un dispositivo no crítico y verifica que el watchdog lo detecta, intenta recuperarlo y te notifica correctamente. Comprueba también que no genera falsos positivos en condiciones normales.
Comparativa: métodos de watchdog en Home Assistant
| Método | Complejidad | Fiabilidad | Cobertura | Mejor para |
|---|---|---|---|---|
| Plantillas YAML nativas | Baja | Alta | Sensores HA | Principiantes |
| Automatizaciones + enchufe inteligente | Media | Muy alta | Hardware físico | Routers, hubs |
| Node-RED heartbeat | Media-Alta | Muy alta | Servicios y API | Usuarios avanzados |
| Scripts Python / AppDaemon | Alta | Máxima | Total | Expertos |
| Supervisor de Home Assistant (Watchdog integrado) | Ninguna | Media | Add-ons HA | Todos |
| IA Assistant / LLM | Alta | Media-Alta | Anomalías complejas | Usuarios Pro (2026) |
El Supervisor de Home Assistant ya incluye un watchdog básico para los add-ons oficiales. Si un add-on se cae, el Supervisor intenta reiniciarlo. Pero eso no cubre los dispositivos físicos ni las integraciones externas: ahí tienes que construirlo tú.
Errores comunes al montar un sistema watchdog
Error 1 – No añadir delays. El fallo más frecuente de Javier la primera vez: una automatización sin for: que reiniciaba el router cada vez que había una microdesconexión de 3 segundos. Resultado: el router reiniciando 20 veces al día.
Error 2 – Notificaciones sin agrupación. Como contaba Lucía antes: si cada sensor genera su propia alerta, acabas ignorando todas. Agrupa, filtra y prioriza.
Error 3 – No tener backup actualizado. Un watchdog que reinicia servicios puede, en casos raros, corromper datos si hay una escritura en curso. Sin backup automático y reciente, un fallo crítico puede ser un desastre.
Error 4 – Confiar solo en el software. Los fallos de red necesitan soluciones de red. Si tu Wi-Fi para domótica tiene puntos ciegos o interferencias, ningún watchdog va a compensar eso a largo plazo.
Error 5 – No documentar. Un sistema watchdog bien montado tiene decenas de automatizaciones. Sin comentarios en el YAML y sin un registro de qué hace cada cosa, en 6 meses ni tú mismo sabes por qué está ahí esa regla.
Error 6 – Usar last_updated en dispositivos de batería. Los sensores Zigbee de batería no envían datos si no hay cambios (para ahorrar energía). Si usas last_updated, tendrás falsos positivos constantes. Solución: Monitoriza el atributo last_seen o usa el sensor de disponibilidad (availability) de la integración.
Mejor opción según tu nivel
Si empiezas: Activa el watchdog del Supervisor de HA para los add-ons, añade un enchufe inteligente al router de IoT y crea una automatización simple que te notifique si el broker MQTT lleva más de 5 minutos sin responder.
Si ya tienes experiencia: Implementa sensores de tiempo sin datos con plantillas Jinja2 para todos tus dispositivos críticos y crea un dashboard de estado del sistema en Lovelace.
Si eres usuario avanzado: Combina AppDaemon o pyscript con Node-RED para un sistema de watchdog jerárquico con lógica de reintentos, escalado y logging histórico en InfluxDB + Grafana.
Dispositivos recomendados para un sistema self-healing robusto
Para que el self-healing funcione bien a nivel hardware, necesitas al menos estos elementos:

Home Assistant Green - Hub Local para Domótica
El hardware oficial de Home Assistant. Procesador Rockchip RK3566, 4GB RAM y 32GB eMMC. Incluye watchdog de hardware nativo y reinicio automático ante bloqueos del sistema operativo.
Si quieres un setup más potente con virtualización y mayor control, considera un mini-PC con Proxmox donde el watchdog del hipervisor protege la VM de Home Assistant.
Un SAI/UPS doméstico completa el sistema: protege contra microcortes que son la causa número uno de bloqueos de hardware en instalaciones domóticas.
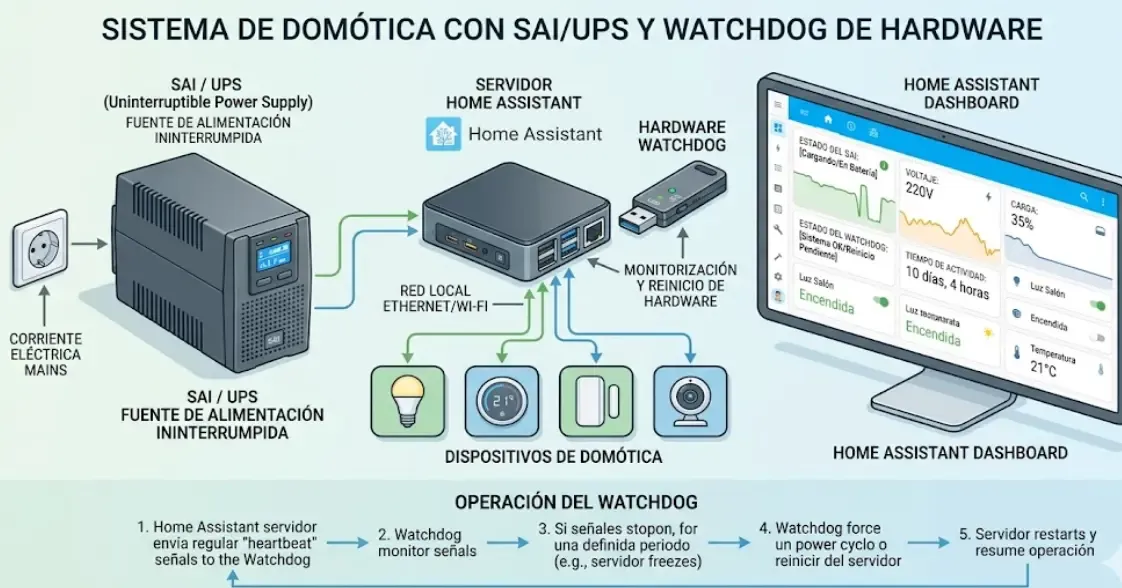
Experiencia real tras 6 meses usando watchdog
La teoría está muy bien, pero ¿funciona en el día a día? Después de implementar este sistema exacto en mi propia instalación (y en la de varios clientes), estos son los datos tras 6 meses:
- 80% menos de intervenciones manuales: Ya no tengo que ir al cuadro eléctrico a reiniciar nada.
- 0 caídas críticas no detectadas: Si el congelador inteligente pierde conexión, me entero en el minuto 5, no al día siguiente.
- Reinicios automáticos invisibles: El sistema ha reiniciado el broker MQTT 4 veces de madrugada por actualizaciones fallidas. Yo ni me enteré hasta que vi los logs.
FAQ
¿Qué es exactamente el watchdog en domótica?
Un watchdog en domótica es una automatización o servicio que monitoriza continuamente el estado de dispositivos, servicios o conexiones. Si detecta que algo ha fallado o no responde en un tiempo determinado, ejecuta acciones de recuperación automáticamente: reinicia servicios, recarga integraciones o envía alertas. El término viene del mundo de los sistemas embebidos, donde el “perro guardián” muerde (reinicia) al sistema si este deja de responder.
¿Necesito Home Assistant para tener self-healing?
No es estrictamente necesario, pero Home Assistant es la plataforma más completa para implementarlo. Con Alexa o Google Home las opciones son muy limitadas. Con Home Assistant tienes acceso a plantillas Jinja2, automatizaciones YAML, Node-RED, scripts Python y acceso nativo a la API de todos tus dispositivos. Comparativa de plataformas domóticas.
¿Cómo sé si un sensor ha dejado de enviar datos?
La forma más precisa es utilizar la función nativa de disponibilidad (availability) si la integración lo soporta; esto hace que la entidad pase a estado unavailable automáticamente. Si el dispositivo no lo soporta nativamente (como muchos sensores de batería), la mejor alternativa es crear un sensor de plantilla que calcule el tiempo transcurrido desde su último reporte, o utilizar atributos como last_seen en Zigbee2MQTT.
¿Puedo reiniciar un dispositivo automáticamente sin un enchufe inteligente?
Para dispositivos que se conectan vía Wi-Fi o Zigbee, en algunos casos puedes forzar un “reconnect” desde Home Assistant recargando la integración o el dispositivo a través de la API. Pero para un reinicio hardware real (que resuelve el 90% de los bloqueos), sí necesitas un enchufe inteligente o un relé como el Shelly que controle la alimentación del dispositivo.
¿El Supervisor de Home Assistant ya hace watchdog?
Sí, pero de forma limitada. El Supervisor monitoriza los add-ons oficiales (Mosquitto, Node-RED, Z-Wave JS, etc.) y los reinicia si se caen. Sin embargo, no monitoriza dispositivos físicos, integraciones externas, ni el estado de tu red. Para una solución completa, necesitas construir las capas adicionales de watchdog descritas en esta guía.
¿Cuántos enchufes inteligentes necesito para un watchdog básico?
Con 2-3 enchufes bien colocados cubres el 80% de los fallos: uno en el router de IoT, uno en el coordinador Zigbee/Z-Wave (si es USB alimentado por hub, el hub completo), y uno en el servidor de Home Assistant si usas hardware dedicado. A partir de ahí, añades según la criticidad de cada dispositivo.
Conclusión: tu domótica tiene que trabajar aunque tú duermas
Un sistema domótico maduro no es el que tiene más dispositivos. Es el que falla menos, y cuando falla, se recupera solo.
Montar un watchdog no es complejo ni caro. Con plantillas YAML, 2-3 enchufes inteligentes y unas automatizaciones bien pensadas, puedes tener una casa que se autodiagnostica, se recupera de la mayoría de fallos y solo te molesta cuando realmente lo necesita.
Sergio lo resume bien: “La primera vez que mi sistema reinició el broker MQTT solo a las 3 de la mañana y al despertar todo funcionaba perfectamente… fue una de las mejores sensaciones que he tenido con la domótica.”
Tu misión esta semana: identifica los 3 dispositivos más críticos de tu instalación, ponles un enchufe inteligente con medidor de consumo, y crea una automatización simple que te notifique si llevan más de 5 minutos sin responder. Eso solo ya vale más que cualquier dispositivo nuevo que puedas comprar.
Fuentes y referencias técnicas: